
Guía Tutorial de Cómo configurar un servidor con LM Studio y utilizarlo con Python
Este tutorial explica cómo iniciar un modelo en LM Studio, configurarlo como servidor y crear una interacción en Python utilizando el script proporcionado, que en esta caso es un script que usa «speech_recognition» para mantener una conversación por voz con cualquier modelo.
1. Configurar LM Studio como servidor
Paso 1: Inicia LM Studio
- LM Studio debe de estar instalado y tener un modelo disponible. Si no sabes como instalarlo mira mi tutorial de instalación.
- Abre la aplicación y dirígete a la pestaña AI Chat.
Paso 2: Carga un modelo
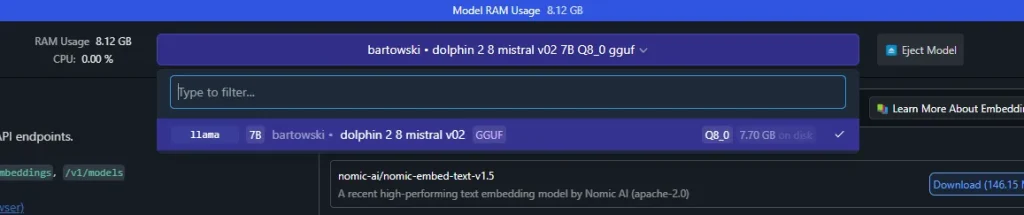
- Haz clic en «Select a model to load» y selecciona el modelo que descargaste previamente (por ejemplo, Llama o Mistral).
- Una vez cargado, verifica que el modelo está activo en la interfaz.
Paso 3: Activar el servidor
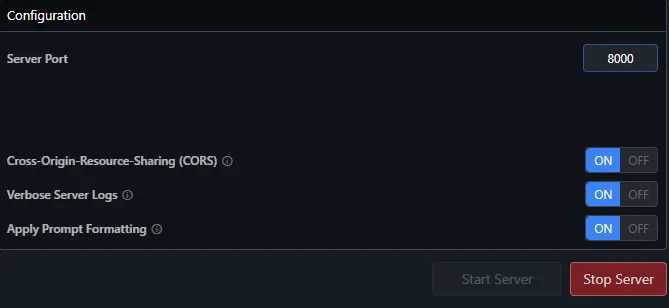
- Ve al recuadro de Ajustes.
- Habilita la opciónes como se muestra en la figura de arriba.
- Define el puerto del servidor. Por defecto, se usa el puerto
1234. Puedes cambiarlo si lo prefieres a 8000 por ejemplo. - Haz clic en Start Server.
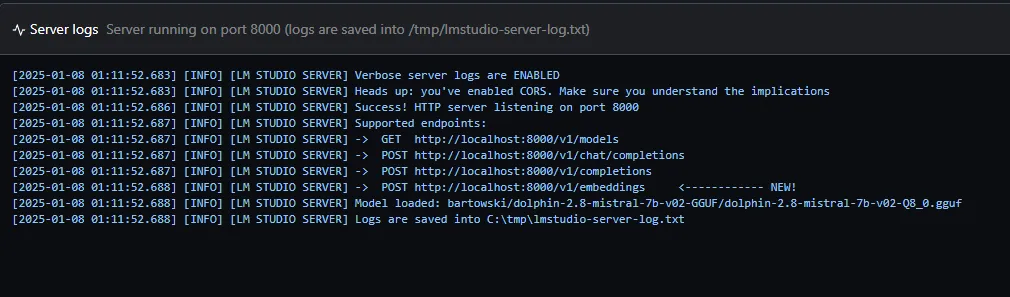
- Verifica que el servidor esté activo. LM Studio mostrará un mensaje indicando que el servidor está ejecutándose.
2. Configurar el entorno Python
Paso 1: Instalar dependencias
Abre una terminal y ejecuta el siguiente comando para instalar las bibliotecas necesarias:
pip install requests pyttsx3 SpeechRecognition
Paso 2: Configura el script
Guarda este código en un archivo, por ejemplo, chatvoz.py.
import speech_recognition as sr
import pyttsx3
import requests
# URL del servidor de LM Studio
SERVER_URL = "http://localhost:8000/v1"
# Configuración de síntesis de voz
engine = pyttsx3.init()
engine.setProperty("rate", 150) # Ajusta la velocidad de la voz
engine.setProperty("volume", 1.0) # Ajusta el volumen de la voz
# Función para reproducir texto en voz
def speak(text):
engine.say(text)
engine.runAndWait()
# Configuración inicial de la conversación (español)
history = [
{"role": "system", "content": "Eres un asistente inteligente. Siempre respondes en español y das respuestas correctas, útiles y bien razonadas."},
]
# Función para obtener el modelo cargado actualmente en el servidor
def get_active_model():
try:
response = requests.get(f"{SERVER_URL}/models")
if response.status_code == 200:
models_data = response.json().get("data", [])
if models_data:
active_model = models_data[0]["id"] # Seleccionar el ID del primer modelo
print(f"🤖 Modelo activo detectado: {active_model}")
return active_model
else:
print("❌ No hay modelos cargados en el servidor. Carga un modelo en LM Studio.")
return None
else:
print(f"❌ Error al obtener modelos: {response.status_code} - {response.text}")
return None
except requests.ConnectionError:
print("❌ No se pudo conectar al servidor de LM Studio.")
return None
# Función para transcribir audio a texto
def transcribe_audio():
recognizer = sr.Recognizer()
with sr.Microphone() as source:
try:
print("🎙️ Escuchando...")
audio = recognizer.listen(source, timeout=5, phrase_time_limit=10)
text = recognizer.recognize_google(audio, language="es-ES")
print(f"📝 Texto transcrito: {text}")
return text
except sr.UnknownValueError:
return None
except sr.RequestError as e:
print(f"❌ Error con el servicio de reconocimiento: {e}")
return None
except sr.WaitTimeoutError:
return None
# Función para enviar texto al modelo y obtener una respuesta
def get_model_response(history, model):
payload = {
"model": model,
"messages": history,
"temperature": 0.7,
"stream": False,
}
try:
response = requests.post(f"{SERVER_URL}/chat/completions", json=payload)
if response.status_code == 200:
reply = response.json()["choices"][0]["message"]["content"]
print(f"🤖 Respuesta del modelo: {reply}")
return {"role": "assistant", "content": reply}
else:
print(f"❌ Error del servidor: {response.status_code} - {response.text}")
return None
except requests.ConnectionError:
print("❌ Error al conectar con el servidor de LM Studio.")
return None
# Flujo principal
def main():
print("💬 Sistema interactivo con LM Studio. Presiona Ctrl+C para salir.\n")
active_model = get_active_model()
if not active_model:
print("❌ No se puede continuar sin un modelo activo.")
return
while True:
# Capturar audio y transcribirlo
user_input = transcribe_audio()
if user_input:
history.append({"role": "user", "content": user_input})
# Obtener respuesta del modelo
response = get_model_response(history, active_model)
if response:
history.append(response)
# Reproducir la respuesta del modelo en español
speak(response["content"])
# Ejecutar el script
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n👋 ¡Hasta luego!")
- Verifica que el valor de
SERVER_URLen el script apunte ahttp://localhost:8000/v1(o al puerto configurado en LM Studio).
3. Ejecutar el script
Paso 1: Iniciar el script
Abre un terminal, navega a la ruta de tu script y ejecútalo con Python:
cd /ruta/de/tu/archivo
python chatvoz.py
Paso 2: Interactuar con el modelo
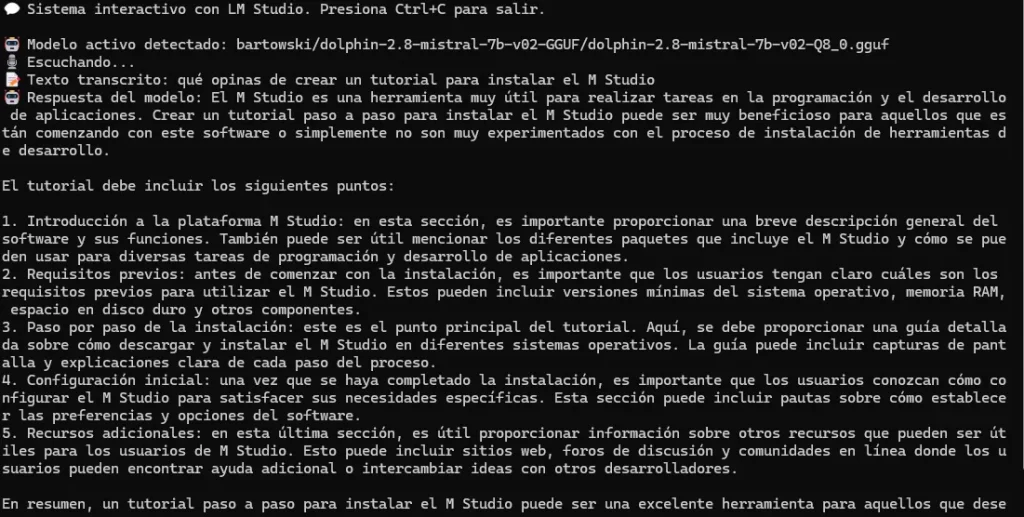
- Habla al micrófono cuando el script indique «🎙️ Escuchando…».
- El texto transcrito será enviado al modelo.
- La respuesta del modelo será leída en voz alta gracias a
pyttsx3. La complejidad y coherencia de la respuesta dependerá del modelo usado.
4. Personalizar el flujo
Puedes adaptar el flujo de interacción:
- Cambia el contexto inicial en la variable «
history» para darle un rol diferente al asistente. - Ajusta la «
temperature» en el payload del modelo para variar la creatividad de las respuestas.
¡La magia de los modelos de lenguaje ahora está en tus manos! Si tienes dudas o problemas, consulta la documentación oficial de LM Studio.